dcgm-exporter で Kubernetes 上の GPU ノードを監視する
はじめに
この記事は CyberAgent Developers Advent Calendar 2020 14日目の記事です。(前日の記事はまだ上がっていないようです・・・)
背景
私が所属する AI事業本部 Strategic Infrastructure Agency (以下 SIA) では現在 NVIDIA の DGX A100 という GPU サーバーを導入し、プライベートクラウドサービスとして提供するために検証を行っています。
DGX A100 のパフォーマンス検証結果は SIA に来てくれたインターン生が執筆したこちらの記事をご覧ください。
[https://www.nvidia.com/ja-jp/data-center/dgx-a100/:embed:cite]
本記事では、 SIA が提供する GPU as a Service や新たにリリースされる SIA AI Platform で DGX A100 を提供するための監視方法を紹介します。
環境
SIA が提供する GPUaaS は Kubernetes 上に構築されており、その Kubernetes 上の DGX A100 に pod がスケジュールされることで GPU を利用してもらうことになります。
構成のイメージ図は以下の画像になります。
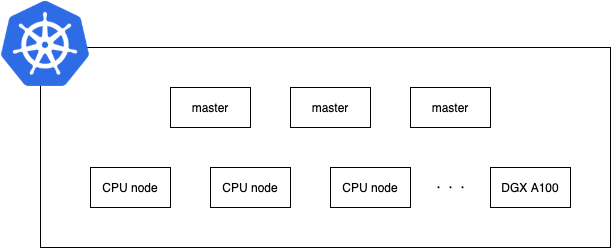
ということで Kubernetes Node の中から GPU Node を選択して dcgm-exporter をデプロイすることになります。
デプロイ
dcgm-exporter
NVIDIA/gpu-monitoring-tools のリポジトリを参考に、Daemonset の manifest に tolerations と nodeSelector を追記します。
apiVersion: apps/v1 kind: DaemonSet metadata: name: "dcgm-exporter" namespace: "monitoring" labels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" spec: updateStrategy: type: RollingUpdate selector: matchLabels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" template: metadata: labels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" name: "dcgm-exporter" spec: tolerations: - key: <gpu-node-taint-key> value: <gpu-node-taint-value> effect: "NoSchedule" containers: - image: "nvidia/dcgm-exporter:2.0.13-2.1.1-ubuntu18.04" env: - name: "DCGM_EXPORTER_LISTEN" value: ":9400" - name: "DCGM_EXPORTER_KUBERNETES" value: "true" name: "dcgm-exporter" ports: - name: "metrics" containerPort: 9400 securityContext: runAsNonRoot: false runAsUser: 0 volumeMounts: - name: "pod-gpu-resources" readOnly: true mountPath: "/var/lib/kubelet/pod-resources" volumes: - name: "pod-gpu-resources" hostPath: path: "/var/lib/kubelet/pod-resources" nodeSelector: <gpu-node-label-key>: <gpu-node-label-value> --- kind: Service apiVersion: v1 metadata: name: "dcgm-exporter" namespace: "monitoring" labels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" spec: selector: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" ports: - name: "metrics" port: 9400
適切な tolerations と nodeSelector を設定することで GPU Node に dcgm-exporter の pod が起動します。
ServiceMonitor
Prometheus は prometheus-operator によって管理されているため dcgm-exporter の ServiceMonitor を作成することで dcgm-exporter を監視対象として追加します。ServiceMonitor も NVIDIA/gpu-monitoring-tools を参考にします。
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: "dcgm-exporter" namespace: "monitoring" labels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" spec: selector: matchLabels: app.kubernetes.io/name: "dcgm-exporter" app.kubernetes.io/version: "2.1.1" endpoints: - port: "metrics" path: "/metrics"
metrics
pod が正常に起動しているか確認します。
$ kubectl -n monitoring port-forward daemonset/dcgm-exporter 9400 &
$ curl localhost:9400/metrics
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).
# TYPE DCGM_FI_DEV_MEM_CLOCK gauge
# HELP DCGM_FI_DEV_MEMORY_TEMP Memory temperature (in C).
# TYPE DCGM_FI_DEV_MEMORY_TEMP gauge
# HELP DCGM_FI_DEV_GPU_TEMP GPU temperature (in C).
# TYPE DCGM_FI_DEV_GPU_TEMP gauge
# HELP DCGM_FI_DEV_POWER_USAGE Power draw (in W).
# TYPE DCGM_FI_DEV_POWER_USAGE gauge
# HELP DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION Total energy consumption since boot (in mJ).
# TYPE DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION counter
# HELP DCGM_FI_DEV_PCIE_TX_THROUGHPUT Total number of bytes transmitted through PCIe TX (in KB) via NVML.
# TYPE DCGM_FI_DEV_PCIE_TX_THROUGHPUT counter
# HELP DCGM_FI_DEV_PCIE_RX_THROUGHPUT Total number of bytes received through PCIe RX (in KB) via NVML.
# TYPE DCGM_FI_DEV_PCIE_RX_THROUGHPUT counter
# HELP DCGM_FI_DEV_PCIE_REPLAY_COUNTER Total number of PCIe retries.
# TYPE DCGM_FI_DEV_PCIE_REPLAY_COUNTER counter
# HELP DCGM_FI_DEV_GPU_UTIL GPU utilization (in %).
# TYPE DCGM_FI_DEV_GPU_UTIL gauge
# HELP DCGM_FI_DEV_MEM_COPY_UTIL Memory utilization (in %).
# TYPE DCGM_FI_DEV_MEM_COPY_UTIL gauge
# HELP DCGM_FI_DEV_ENC_UTIL Encoder utilization (in %).
# TYPE DCGM_FI_DEV_ENC_UTIL gauge
# HELP DCGM_FI_DEV_DEC_UTIL Decoder utilization (in %).
# TYPE DCGM_FI_DEV_DEC_UTIL gauge
# HELP DCGM_FI_DEV_XID_ERRORS Value of the last XID error encountered.
# TYPE DCGM_FI_DEV_XID_ERRORS gauge
# HELP DCGM_FI_DEV_POWER_VIOLATION Throttling duration due to power constraints (in us).
# TYPE DCGM_FI_DEV_POWER_VIOLATION counter
# HELP DCGM_FI_DEV_THERMAL_VIOLATION Throttling duration due to thermal constraints (in us).
# TYPE DCGM_FI_DEV_THERMAL_VIOLATION counter
# HELP DCGM_FI_DEV_SYNC_BOOST_VIOLATION Throttling duration due to sync-boost constraints (in us).
# TYPE DCGM_FI_DEV_SYNC_BOOST_VIOLATION counter
# HELP DCGM_FI_DEV_BOARD_LIMIT_VIOLATION Throttling duration due to board limit constraints (in us).
# TYPE DCGM_FI_DEV_BOARD_LIMIT_VIOLATION counter
# HELP DCGM_FI_DEV_LOW_UTIL_VIOLATION Throttling duration due to low utilization (in us).
# TYPE DCGM_FI_DEV_LOW_UTIL_VIOLATION counter
# HELP DCGM_FI_DEV_RELIABILITY_VIOLATION Throttling duration due to reliability constraints (in us).
# TYPE DCGM_FI_DEV_RELIABILITY_VIOLATION counter
# HELP DCGM_FI_DEV_FB_FREE Framebuffer memory free (in MiB).
# TYPE DCGM_FI_DEV_FB_FREE gauge
# HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB).
# TYPE DCGM_FI_DEV_FB_USED gauge
# HELP DCGM_FI_DEV_ECC_SBE_VOL_TOTAL Total number of single-bit volatile ECC errors.
# TYPE DCGM_FI_DEV_ECC_SBE_VOL_TOTAL counter
# HELP DCGM_FI_DEV_ECC_DBE_VOL_TOTAL Total number of double-bit volatile ECC errors.
# TYPE DCGM_FI_DEV_ECC_DBE_VOL_TOTAL counter
# HELP DCGM_FI_DEV_ECC_SBE_AGG_TOTAL Total number of single-bit persistent ECC errors.
# TYPE DCGM_FI_DEV_ECC_SBE_AGG_TOTAL counter
# HELP DCGM_FI_DEV_ECC_DBE_AGG_TOTAL Total number of double-bit persistent ECC errors.
# TYPE DCGM_FI_DEV_ECC_DBE_AGG_TOTAL counter
# HELP DCGM_FI_DEV_RETIRED_SBE Total number of retired pages due to single-bit errors.
# TYPE DCGM_FI_DEV_RETIRED_SBE counter
# HELP DCGM_FI_DEV_RETIRED_DBE Total number of retired pages due to double-bit errors.
# TYPE DCGM_FI_DEV_RETIRED_DBE counter
# HELP DCGM_FI_DEV_RETIRED_PENDING Total number of pages pending retirement.
# TYPE DCGM_FI_DEV_RETIRED_PENDING counter
# HELP DCGM_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_TOTAL Total number of NVLink flow-control CRC errors.
# TYPE DCGM_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_TOTAL counter
# HELP DCGM_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_TOTAL Total number of NVLink data CRC errors.
# TYPE DCGM_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_TOTAL counter
# HELP DCGM_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_TOTAL Total number of NVLink retries.
# TYPE DCGM_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_TOTAL counter
# HELP DCGM_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_TOTAL Total number of NVLink recovery errors.
# TYPE DCGM_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_TOTAL counter
# HELP DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL Total number of NVLink bandwidth counters for all lanes
# TYPE DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL counter
DCGM_FI_DEV_SM_CLOCK{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 210
DCGM_FI_DEV_MEM_CLOCK{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 1215
DCGM_FI_DEV_MEMORY_TEMP{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 25
DCGM_FI_DEV_GPU_TEMP{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 26
DCGM_FI_DEV_POWER_USAGE{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 42.775000
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 19160364272
DCGM_FI_DEV_PCIE_TX_THROUGHPUT{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 36296895
DCGM_FI_DEV_PCIE_RX_THROUGHPUT{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 13653238
DCGM_FI_DEV_PCIE_REPLAY_COUNTER{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_GPU_UTIL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_MEM_COPY_UTIL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_ENC_UTIL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_DEC_UTIL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_XID_ERRORS{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_POWER_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_THERMAL_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_SYNC_BOOST_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_BOARD_LIMIT_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_LOW_UTIL_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_RELIABILITY_VIOLATION{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_FB_FREE{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775795
DCGM_FI_DEV_FB_USED{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775795
DCGM_FI_DEV_ECC_SBE_VOL_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_ECC_DBE_VOL_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_ECC_SBE_AGG_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_ECC_DBE_AGG_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 0
DCGM_FI_DEV_RETIRED_SBE{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_RETIRED_DBE{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_RETIRED_PENDING{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_NVLINK_CRC_FLIT_ERROR_COUNT_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_NVLINK_CRC_DATA_ERROR_COUNT_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_NVLINK_REPLAY_ERROR_COUNT_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_NVLINK_RECOVERY_ERROR_COUNT_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL{gpu="0", UUID="hoge-fuga-piyo",container="",namespace="",pod=""} 9223372036854775794
[以下略]
正常に起動していることが確認できました。
Prometheus
続いて、Prometheus 経由で正常に監視できているかを確認します
$ kubectl -n monitoring port-forward svc/prometheus-k8s 9090
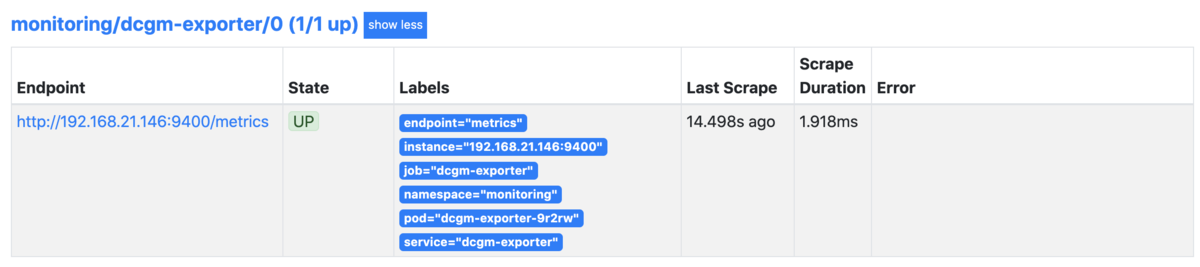
prometheus-operator の ServiceMonitor は機能しているようです。
Grafana
同じく NVIDIA/gpu-monitoring-tools の Dashboard を利用します。
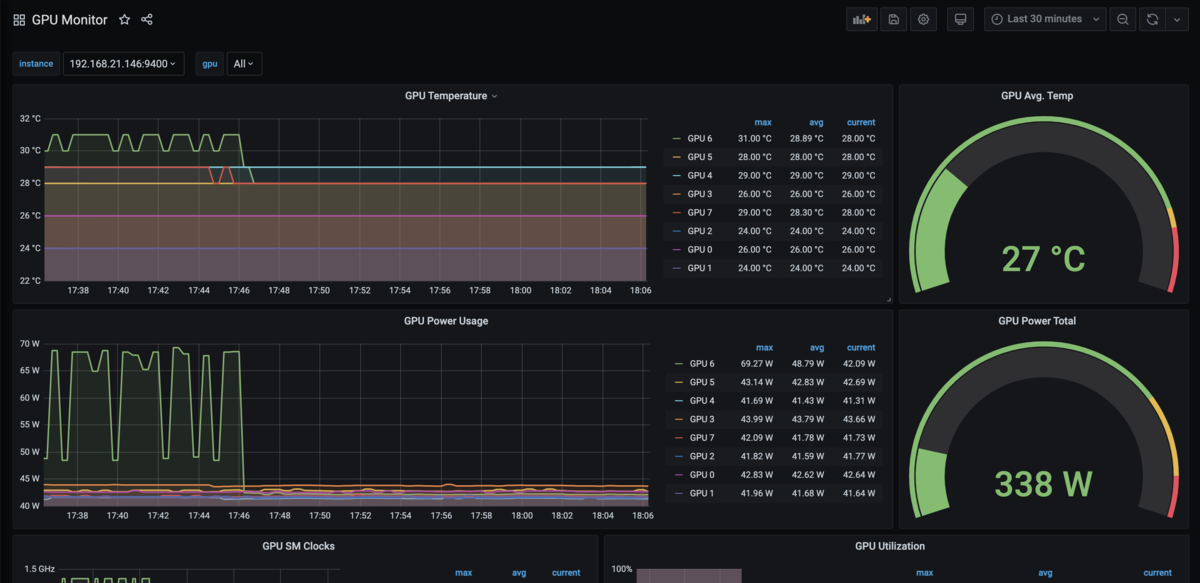
AlertManager
後日追記します。
まとめ
アラート設定など未完な部分があるので後日追記させていただきます。
現在、最新の 2.1.1 が DGX A100 の nvidia-docker 上で動かず 1.7.2 を利用しています。その影響か GPU Core と Memory の Utilization が正常に取得できないという問題に遭遇しており、現在 issue を立てていますが17日間音沙汰がなく困っています・・・
おわりに
明日はイワケンさんの担当になります!